eCognition8分类初级教程

1:要有影像对象层,即影像要先做分割。
2:明确知道有什么地类。
3:描述地类的特征和阈值。
本次实验所用数据为高分一号的多光谱影像,共有蓝,绿,红,近红四个通道。像素分辨率为8m。

在eCognition中对绿光波段进行增强显示设置如下:
对绿光波段增强之后的显示效果:

分类之前需要对图像进行分割,分割采用的方法是多尺度分割。对图像进行多尺度分割完成后的影像:
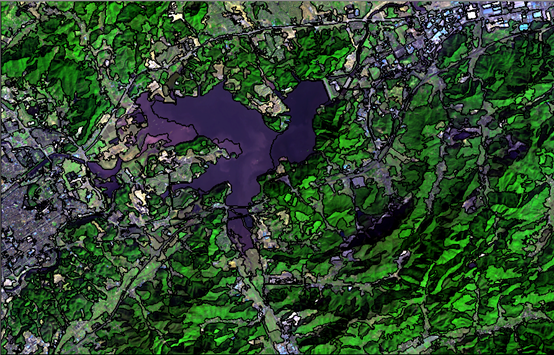
下一步我们就可以开始进行分割。
▲ahq滤蓝光护目屏采用ahq专利技术,对于380~450nm波段蓝光过滤率超过61%,380~420nm波段蓝光过滤率达到87%,吸收uv300~400nm更是高达99%,并可以减少蓝光所产生炫光,经过实际测试,长时间看屏幕眼睛疲劳感和眩晕感有所降低,尤其是对于近视患者。处理方式:在分割影像之后,添加一条规则将背景提取出来,有的背景对应的波段均值是0,有的背景对应的波段均值即使不是0,也会比正常影像中的分割对象的均值小很多,因此可以利用这一点首先将背景作为一个类别提取出来,如图1所示为原始影像/分割结果影像/背景区域的波段均值。所有选择性吸收涂层的构造基本上分为两个部分:红外反射底层和太阳光谱吸收层。
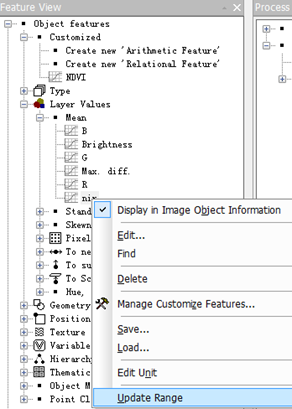

点击之后发现图像如下所示:

图像变成了黑白色,一块块小图斑就是分割之后的一片一片小区域,鼠标放上去还可以显示当前块的均值。在Feature View 底部的小框上打勾

这里现实的两个值分别是上界值和下界值,在当小图斑的值小于下界的值时,图斑会显示为黑色。当小图斑的值介于上界值和下界值时,图斑会显示蓝色或绿色。当小图斑的值大于上界值,图斑会显示成白色或灰色。这两个值我们可以通过按钮调节,直到找到合适的阈值来区分水体。
在configuration这上面右键,选择查找,输入scaling,在右框找到scaling,右键scaling修改。3、如果还是不行,绝招:先在ms-dos下输入ipconfig /release 再输入 ipconfig /renew 就可以了右键点网上邻居 属性 本地连接 右键 启用联接如果不行的话操作如下:右键点网上邻居 属性 本地连接 右键 属性 看看有没有tcp/ip协议 没有就点 协议 安装 选 microsoft tcp/ip 确定 在双击点开 tcp/ip协议 输入本机 ip 如:192.168.0.2 子网掩码 255.255.255.0 默认网关 输入你的主机ip 如:192.168.0.1(需要看你的主机) 确定 重启机器。在开始搜索框输入regedit打开注册表,定位到hkey_local_machine------system------controlset001-------control-------graphicsdrivers-------configuration------然后右键点击configuration,选择查找,输入scaling,在右框内即可看到scaling,右键scaling选择修改,将数值改为3即可,原值为4以上就是在win7系统下,a卡的笔记本用户全屏玩cf的设置,此设置我测试过,一般是结束游戏以后不会自动更改电脑的分辨率,但是偶尔会有更改分辨率的情况发生(原因不明),这时候你可以选择重启电脑就可以了。
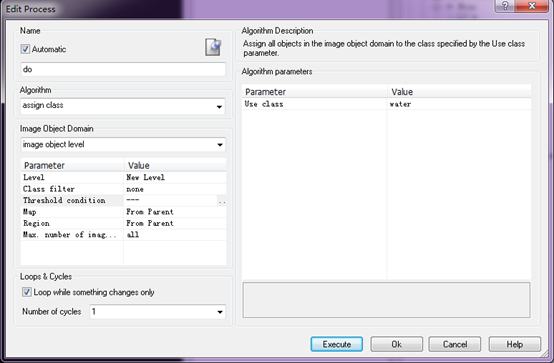
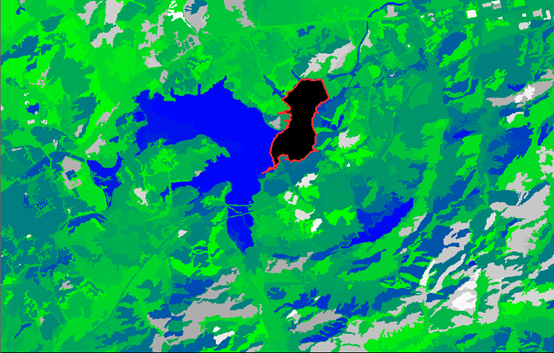
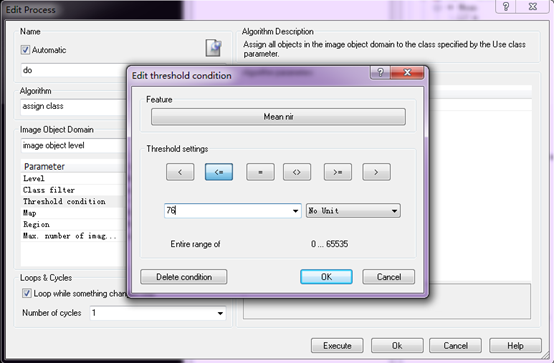
最关键是选择Threshold condition。设置nir<=76的作为水体。
然后执行分类就可以得到分类结果。
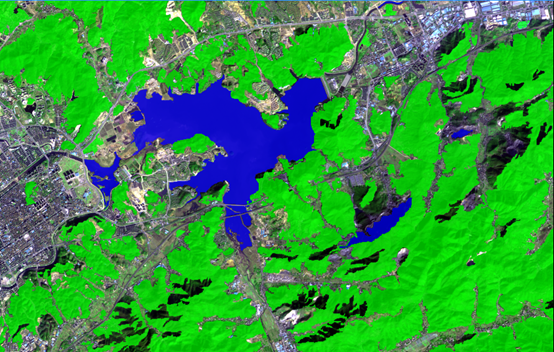
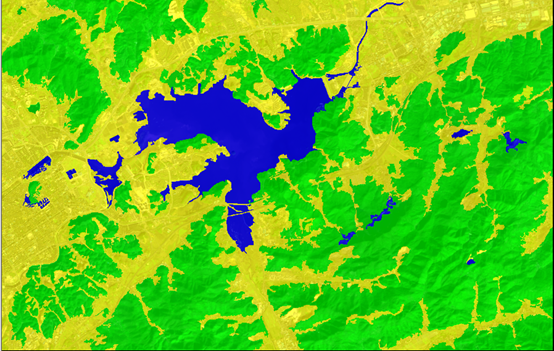
可以看出来大部分水体已经提取出来,但是还是存在漏判和误判。
使用植被指数NDVI提取植被,NDVI=(近红外波段-红色波段)/(近红外波段+红色波段),但是在eCognition中没有关于NDVI的定义,我们需要自定义这个特征,选择Feature View->Object feature->Customized->Creat new ‘Arithmetic Feature’,在弹出的对话框中,填写特征名字NDVI以及计算公式点击确定就可以。


从这里可以看到iso文件中的所有信息,否则是不能继续下面的步骤的,然后下载即可,找到资源工具/,经过小编的一番努力,右键点击,全部点下一步完成ultraiso软件的安装,点击窗口中的“打开”按钮,但是没有详细的步骤,就会安装在如图所示的默认目录下面,可以选择软件安装的目录。2、 如果你下的文件夹中,并没有这样的文件,则可以:“我的电脑”——“右键”属性——“设备管理器”中找到末安装驱动对应的的名称,按右键,“属性”——驱动程序——升级驱动程序,再下一步:抬定位置浏览,找到你的驱动的对应的位置,即可,这时还有版本上的区别如:win98,me2000xp选择正确目录。解决步骤首先打开运行命令win7点开始菜单 找到运行win8快捷键:win+x输入regedit打开注册表后按照下面顺序找到 main目录-》 hkey_current_user\software\microsoft\internet explorer\main找到 main 目录后右键选择权限 具体请看图点击权限后选择高级打开高级选项后win7系统请在图片那个位置 (包括可从该对象的父项继承的权限前打上对勾)win8系统直接启用继承设置完毕后全部点确定 这样ie10浏览器就能打开了。
绿色部分就是提取出来的植被
陆地分类和前面两种有所区别,因为陆地中包含地物太多,难以找到特征或者阈值来分类,所以我这里将图像中除了水体和植被之外剩下的作为陆地。因此在规则集设置时候如下图所示,Class filter设置为unclassified,没有阈值条件,Use class设置为land,这样就表示将所有未分类的全部分类成陆地。
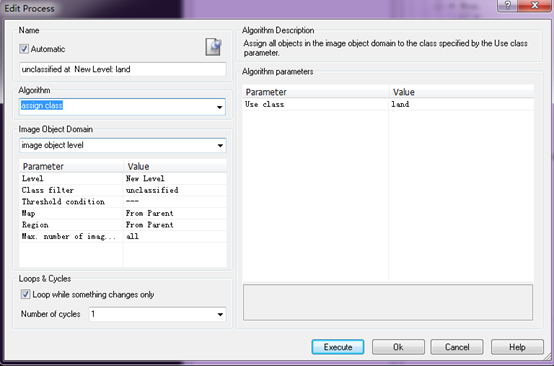
黄色部分就是提取出来的陆地
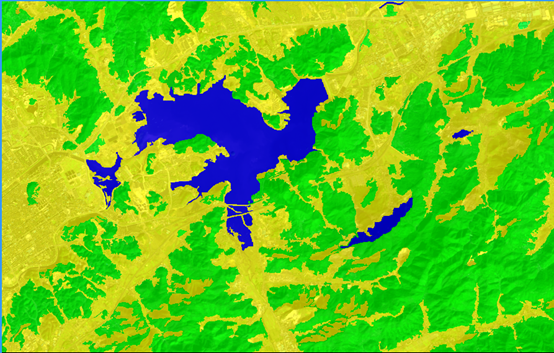
进行分类之前首先要创建地类,然后对地类进行类描述。因为是隶属度分类,我们需要一个隶属度函数来帮我们确定隶属度。根据前面做的阈值分类的经验我们大概可以知道水体在近红外波段的值是多少。在Class Hierarchy窗口下双击water编辑水体的类描述ecognition 导出分类结果,Contained->and(min)->Object features->Layer Values->Mean->nir选择一个适合我们的隶属度函数。
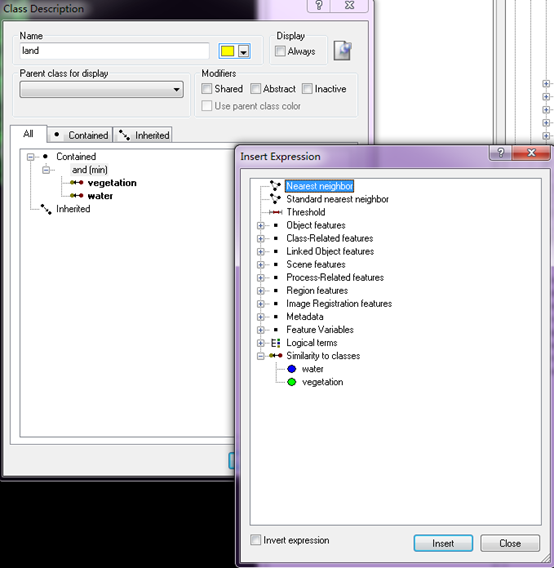
对vegetation的描述类似。只是在选择特征时候要选择我们自定义NDVI特征。在对land进行类描述时候是不一样的,因为前面将不是植被,不是水体的其他区域都作为陆地。
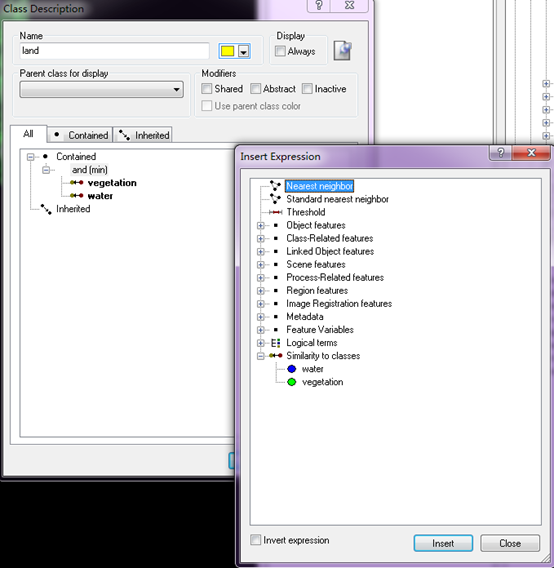

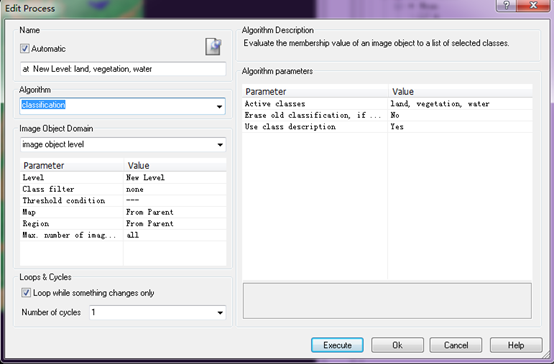
在类描述中选择Similarity to classes,双击water和vegetation,然后再分别右键选择这个两个类描述,选择Invert Expression。这样三个地类的类描述我们都完成了。接下里就可以选择算法进行分类了,同样的,在Process Tree中右键Append New,Algorithm选择classfication,右边的Active classes选择需要分类的三个地类,Use class description选择Yes就可以了。

分割结果如下所示:
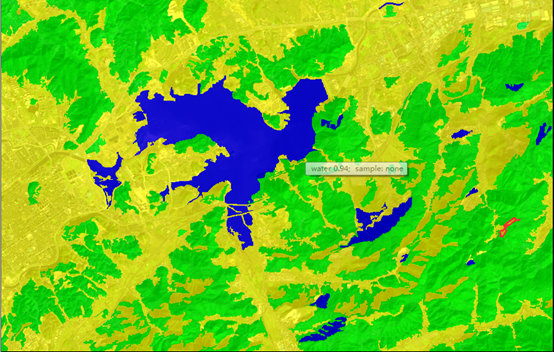
与阈值分割不同的是鼠标移到结果上面会有不同的隶属度的显示。阈值分割时隶属度全部为1.
说 明 页:说明页列表、添加说明页、删除说明页、说明页分类、添加说明页分类、修改说明页分类、删除说明页分类。分类里面不能添加ivar是因为分类本身并不是一个真正的类,它并没有自己的isa .借用一位博主的话: "类最开始生成了很多基本属性,比如ivarlist,methodlist,分类只会将自己的method attach到主类,并不会影响到主类的ivarlist。新闻资讯:新闻列表(可按添加时间,分类,属性筛选)、添加新闻、删除新闻、搜索新闻、添加分类,删除分类,修改分类、分类排名、新闻属性列表ecognition 导出分类结果,、添加属性、删除属性、修改属性。
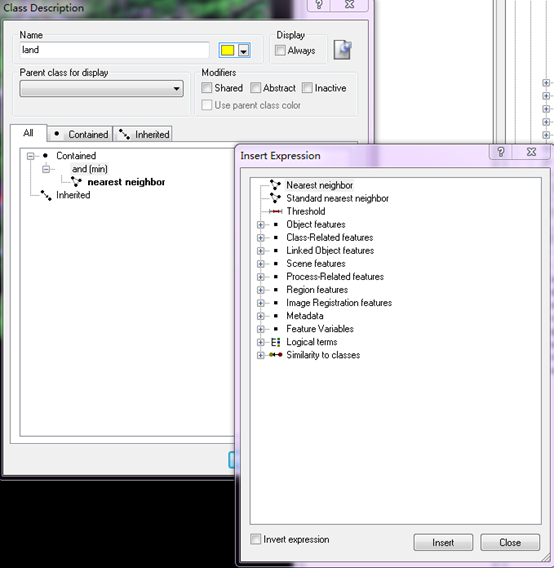
然后选择and(min)->nearest neighbor->Object features->Layer Value->Mean和Standard deviation
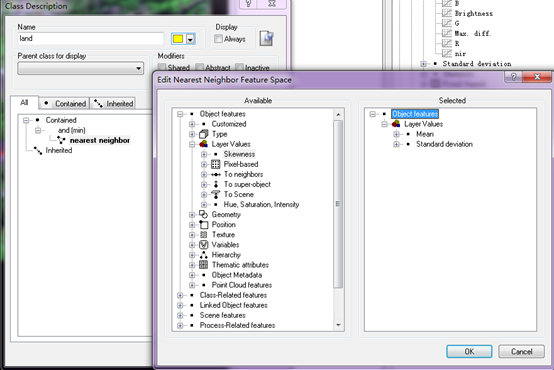
最后类描述如下:
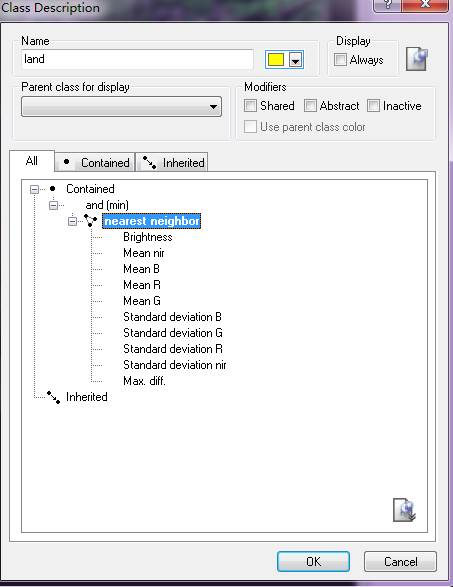
对于water和vegetation两类的类描述也是如此。
最邻近法属于监督分类,那么我们就需要选择样本。首先,在eCognition中调出选择样本的工具栏
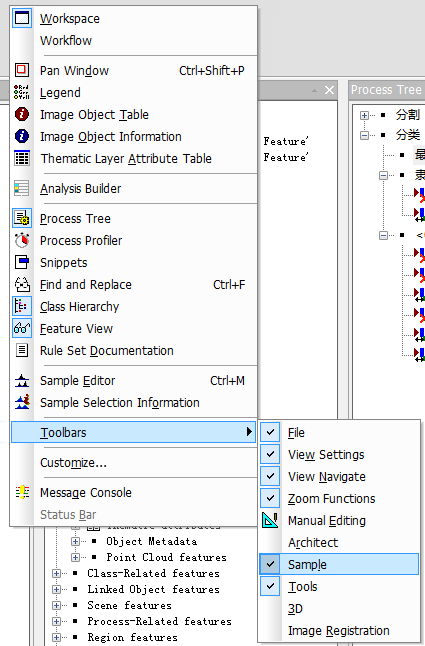
下图就是样本选择工具栏:
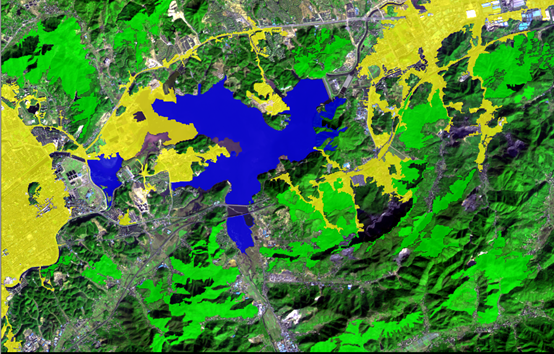

选完样本之后就可以进行分类了。和隶属度分类一样还是选择classification这个算法。右边的Active classes选择需要分类的三个地类,Use class description选择Yes就可以了。
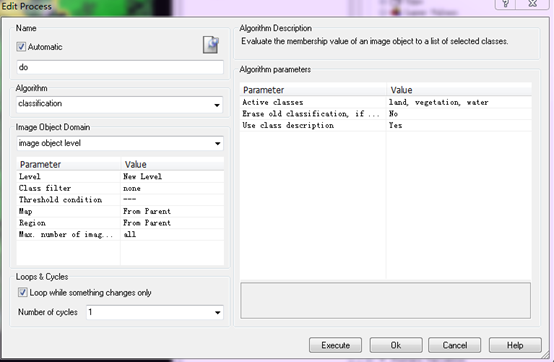
分类结果:

决策数分类是监督分类也需要选择样本,但是不需要类描述,在决策数分类时对于地类的类描述可以首先删除。决策数分类时选样本的方式和最邻近法分类有所区别,先调出决策数分类需要的样本选择工具栏。
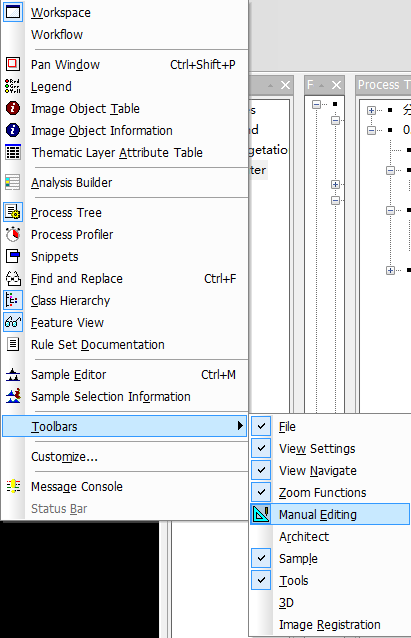
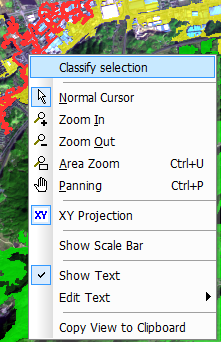
下图就是我们需要的工具栏,在第二个下拉框中选择地类开始挑选样本,左键点击样本,再右键选择Classify selection就可以了,对三个地类分别选择样本。

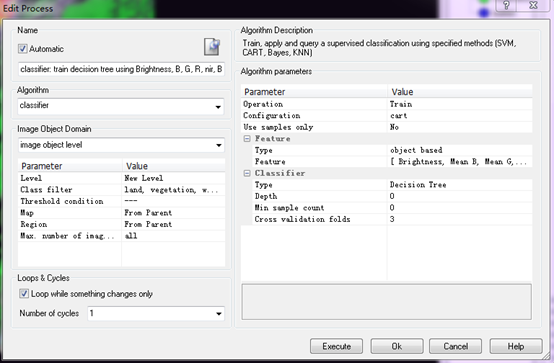
样本选择完毕,下一步是训练决策树模型,选择的算法是classifier。因为这里训练面向的是对象级别,所以在Image Object Domain中选择image object leval。Class filter选择设定好的三个地类。Feature选择Object features->Layer Value->Mean和Standard deviation。这里Configuration里面表示训练生成的文件,我命名为cart。最后规则集的设置如下:
直观地看,计算一般是指运用事先规定的规则,将一组数值变换为另一(所需的)数值的过程.对某一类问题,如果能找到一组确定的规则,按这组规则,当给出这类问题中的任一具体问题后,就可以完全机械地在有限步内求出结果,则说这类问题是可计算的.这种规则就是算法,这类可计算问题也可称之为存在算法的问题.这就是直观上的能行可计算或算法可计算的概念.。在上面的例子中,如果文件[.c]存在,那么就直接调用c的编译器的隐含规则,如果没有[.c]文件,但有一个[.y]文件,那么yacc的隐含规则会被调用,生成[.c]文件,然后,再调用c编译的隐含规则最终由[.c]生成[.o]文件,达到目标。将被标记的原始数据集分成训练集和检验集两份,训练集用于训练分类模型,检验集用于评估分类模型性能。
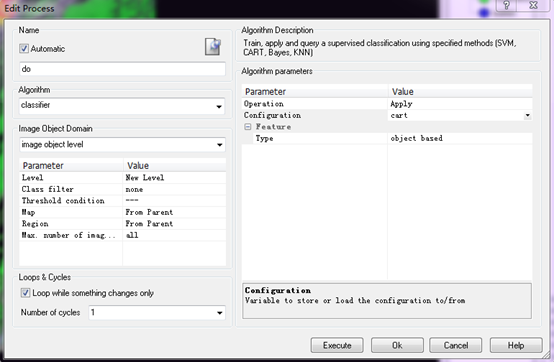
分类结果如下:
说 明 页:说明页列表、添加说明页、删除说明页、说明页分类、添加说明页分类、修改说明页分类、删除说明页分类。适用于这个计划的15类母婴类商品如下(点击可查看):注意:为了激活baby registry,在下面的15个分类中,最少选择其中的10个分类,每个分类最少选择1件商品,也就是最少添加10件商品到列表中。新闻资讯:新闻列表(可按添加时间,分类,属性筛选)、添加新闻、删除新闻、搜索新闻、添加分类,删除分类,修改分类、分类排名、新闻属性列表,、添加属性、删除属性、修改属性。
-

-
张祥钰
小伙体挺不容易的
-
裴虔余
iphone是什么
差了一代