科学网—深度学习在目标视觉检测中的应用进展与展望(3)
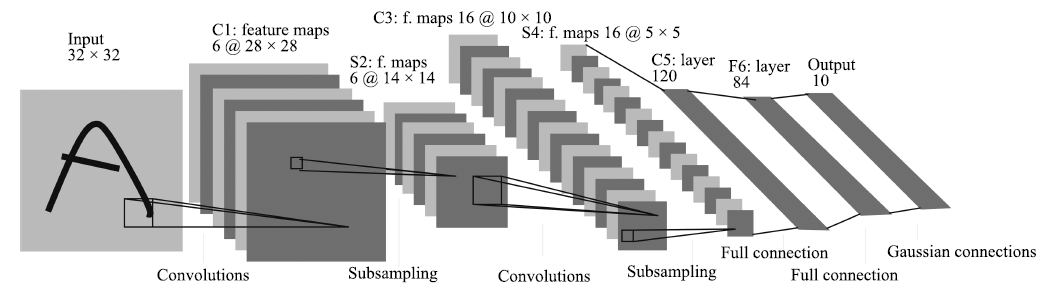
图 3 卷积神经网络的基本结构[]
Figure 3 Basic structure of convolutional neural network[]
3.2 AlexNet及其改进模型
这里需要补充的一点是,并不是参与分类的特征越多,分类的精度就越高,因为分类特征越多也可能带来特征冗余的现象,会造成计算量的增加,分类效率的降低,甚至是分类精度的降低。据了解,dpu 是面向深度学习 (dl) 应用的可编程通用计算平台,可以处理诸如图像和视频的分类 、分割、检测 、跟踪 等任务。衣+视觉引擎基于海量数据的深度学习,检测视频或图像中的万类物体,其中常用物体超过300类常用物体,并通过特征分析,准确判断物体类目。
表 1 经典CNN模型在ILSVRC图像分类任务上的性能对比
Table 1 Performance comparison of classical CNN model in image classification task of ILSVRC
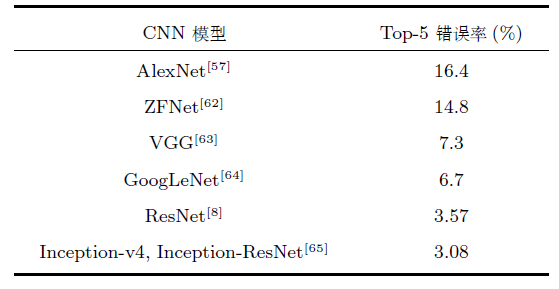
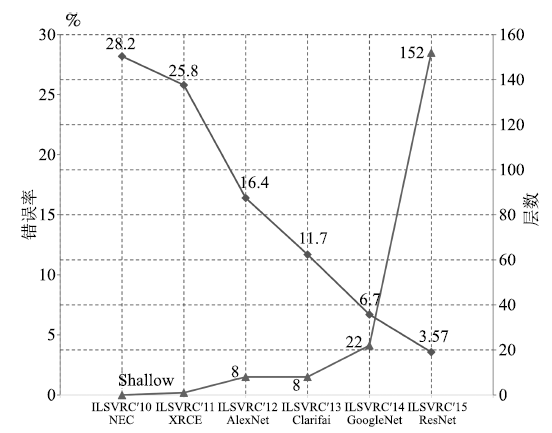
图 4 ILSVRC图像分类任务历年冠军方法的Top-5错误率(下降曲线)和网络层数(上升曲线)
Figure 4 Top-5 error rate (descent curve) and network layers (rise curve) of the champion methods each year in image classification task of ILSVRC
AlexNet[]在ILSVRC 2012图像分类任务上取得了Top-5错误率16.4%, 明显优于基于传统方法的第2名的结果(Top-5错误率26.2%). AlexNet神经网络由5个卷积层、最大池化层、Dropout层和3个全连接层组成, 网络能够对1 000个图像类型进行分类.由于AlexNet的成功, 许多研究人员开始关注和改进CNN结构. Zeiler等[]通过可视化AlexNet网络, 发现第1层滤波器是非常高频和低频信息的混合, 很少覆盖中间频率.并且由于第2层卷积采用比较大的步长, 导致第2层出现混叠失真(Aliasing artifacts).为了解决这些问题, 他们将第1层滤波器的尺寸从11 × 11减小到7 × 7, 将步长从4减小到2, 形成ZFNet模型. ZFNet在网络的第1层和第2层保留了更多信息, 降低了分类错误率.
imgproc-图像处理模块,包括线性非线性滤波,几何图像变化(尺寸变换、仿射、透视、基于表的映射),图像域卷积,直方图等。mlpconv是一个微小的多层卷积网络,即在线性卷积后面增加若干层1x1的卷积,这样可以提取出高度非线性特征。已知输入信号序列为零中频线性调频信号,根据题目要求在第二节已求出输入信号序列,因此根据公式易求出匹配滤波系数序列h(n),但为保证利用fft计算线性卷积不出现混叠失真,则循环卷积长度必须满足l=n+m-1,其中l为卷积长度,n和m分别为两卷积序列长度。
Szegedy等[]提出了一种新的深度CNN模型GoogLeNet, 习惯上称为Inception-v1.只利用了比AlexNet[]少12倍的参数, 但分类错误率更低. GoogLeNet采用Inception结构, 上一层的输出经过1×1、3×3、5×5的卷积层和3×3的池化层, 然后拼接在一起作为Inception的输出.并且在3×3、5 × 5卷积层之前采用1×1卷积层来降维, 既增加了网络的深度, 又减少了网络参数. Inception结构既提高了网络对尺度的适应性, 又提高了网络计算资源的利用率.但是深度网络在训练时, 由于模型参数在不断更新, 各层输入的概率分布在不断变化, 因此必须使用较小的学习率和较好的参数初值, 导致网络训练很慢, 同时也导致采用饱和的非线性激活函数(例如Sigmoid)时训练困难.为了解决这些问题, 又出现了GoogLeNet的续作Inception-v2[].它加入了批规范化(Batch normalization)处理, 将每一层的输出都进行规范化, 保持各层输入的分布稳定, 使得梯度受参数初值的影响减小.批规范化加快了网络训练速度, 并且在一定程度上起到正则化的作用. Inception-v2在ILSVRC 2012图像分类任务上的Top-5错误率降低到4.8%.随着Szegedy等研究GoogLeNet的深入, 网络的复杂度也逐渐提高. Inception-v3[]变得更加复杂, 它通过将大的滤波器拆解成若干个小的滤波器的堆叠, 在不降低网络性能的基础上, 增加了网络的深度和非线性. Inception-v3在ILSVRC 2012图像分类任务上的Top-5错误率降低到3.5%.
2015年, He等[]提出了深度高达上百层的残差网络ResNet, 网络层数(152层)比以往任何成功的神经网络的层数多5倍以上, 在ImageNet测试集上的图像分类错误率低至3.57%. ResNet使用一种全新的残差学习策略来指导网络结构的设计, 重新定义了网络中信息流动的方式, 重构了网络学习的过程, 很好地解决了深度神经网络层数与错误率之间的矛盾(即网络达到一定层数后, 更深的网络导致更高的训练和测试错误率). ResNet具有很强的通用性, 不但在图像分类任务, 而且在ImageNet数据集的目标检测、目标定位任务以及MS COCO数据集的目标检测和分割任务上都取得了当时最好的竞赛成绩.此后, Szegedy等[]通过将Inception结构与ResNet结构相结合, 提出了Inception-ResNet-v1和Inception-ResNet-v2两种混合网络, 极大地加快了训练速度, 并且性能也有所提升.除了这种混合结构, 他们还设计了一个更深更优化的Inception-v4网络, 单纯依靠Inception结构, 达到与Inception-ResNet-v2相近的性能. Szegedy等[]将3个Inception-ResNet-v2网络和1个Inception-v4网络相集成, 在ILSVRC 2012图像分类任务上的Top-5错误率降低到3.08%.
3.3 深度学习在目标视觉检测中的应用
视频序列图像动态目标,对目标进行特征抽取、查询,处理进行整体的或局部的内容检索,可采用全局特征或局部的特征。人工智能/深度学习:如cnn人脸检测,图像分类。据了解,dpu 是面向深度学习 (dl) 应用的可编程通用计算平台,可以处理诸如图像和视频的分类 、分割、检测 、跟踪 等任务。
接下来, 我们从基于区域建议的方法和无区域建议的方法两方面来介绍深度学习在目标视觉检测中的研究现状.
3.3.1 基于区域建议(Proposal-based)的方法
一般的,对于包含有大量非规则形状和高度突变的场景,比较适合提取点状特征,因为提取线段、区域等特征既困难又会引入误差:对于具有规则结构的场景,若线段和区域特征的提取和描述比较容易且误差较小,应提取线段特征以实现快速匹配。使用sift算法进行识别(特征点的提取并用特征向量对特征点描述,接着当前视图的特征向量与目标对象的特征向量进行匹配)。 3.4 空间关系特征 提取图像空间关系特征可以有两种方法:一种方法是首先对图像进行自动分割,划分出图像中所包含的对象或颜色区域,然后根据这些区域提取图像特征,并建立索引。

图 5 R-CNN的计算流程[]
Figure 5 Calculation flow of R-CNN[]
3.4 空间关系特征 提取图像空间关系特征可以有两种方法:一种方法是首先对图像进行自动分割,划分出图像中所包含的对象或颜色区域,然后根据这些区域提取图像特征,并建立索引。另外图像金字塔的层取 得不足够紧密也会使得尺度有误差,后面的特征向量提取同样依赖相应的尺度,发明者在这个问题上的折中解决方法是取适量的层然后进行插值。在极值比较的过程中,每一组图像的首末两层是无法进行极值比较的,为了满足尺度变化的连续性(下面有详解),我们在每一组图像的顶层继续用高斯模糊生成了 3 幅图像,高斯金字塔有每组s+3层图像。
3.4 空间关系特征 提取图像空间关系特征可以有两种方法:一种方法是首先对图像进行自动分割,划分出图像中所包含的对象或颜色区域,然后根据这些区域提取图像特征,并建立索引。指纹图像预处理介于采集指纹原始图像和提取特征点之间的阶段,有时也 将二值化和细化归于提取特征点阶段。虚线上方是反垃圾算法的训练流程,最开始是基于nlp自然语言处理进行,首先对文本数据(垃圾贴和正常贴)进行分词,这些分词需要定期更新,然后再对帖子进行特征处理和选取,将提取之后的特征送入分类器模型训练,其中分类器包括贝叶斯分类、逻辑回归分类等,通过训练输出分类模型的结果。
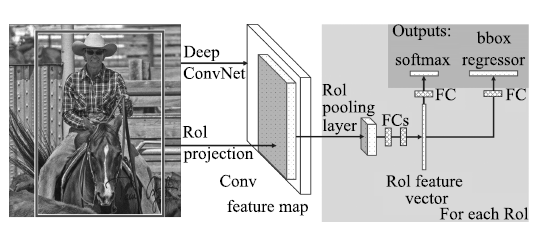
图 6 Fast R-CNN的计算流程[]
Figure 6 Calculation flow of Fast R-CNN[]
为了解决区域建议步骤消耗大量计算资源, 导致目标检测不能实时的问题, Ren等[]提出区域建议网络(Region proposal network, RPN), 并且把RPN和Fast R-CNN融合到一个统一的网络(称为Faster R-CNN), 共享卷积特征. RPN将一整幅图像作为输入, 输出一系列的矩形候选区域.它是一个全卷积网络模型, 通过在与Fast R-CNN共享卷积层的最后一层输出的特征图上滑动一个小型网络, 这个网络与特征图上的小窗口全连接, 每个滑动窗口映射到一个低维的特征向量, 再输入给两个并列的全连接层, 即分类层(cls layer)和边框回归层(reg layer), 由于网络是以滑动窗的形式来进行操作, 所以全连接层的参数在所有空间位置是共享的.因此该结构由一个卷积层后连接两个并列的1×1卷积层实现, 如所示.对于每个小窗口, 以中心点为基准点选取k (作者采用k=9)个不同尺度、不同长宽比的Anchor.对于每个Anchor, 分类层输出2个值, 分别表示其属于目标的概率与属于背景的概率; 边框回归层输出4个值, 表示其坐标位置. RPN的提出, 以及与Fast R-CNN进行卷积特征的共享, 使得区域建议步骤的计算代价很小.与以前的方法相比, 提取的候选区域数量大幅减少, 同时改进了候选区域的质量, 从而提高了整个目标检测网络的性能, 几乎可以做到实时检测.在PASCAL VOC 2007和2012、MS COCO等数据集上, Faster R-CNN取得了当时最高的检测精度.但是由于深度特征丢失了物体的细节信息, 造成定位性能差, Faster R-CNN对小尺寸物体的检测效果不好.
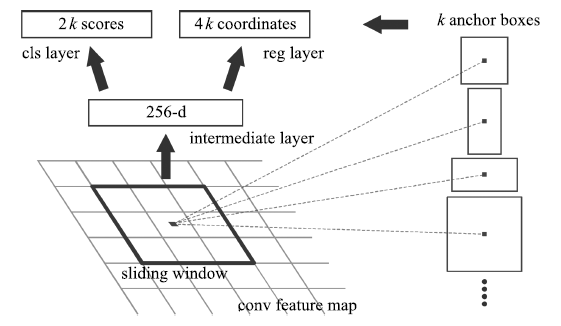
图 7 区域建议网络的基本结构[]
Figure 7 Basic structure of region proposal network[]
当两个运动方向的物体做任何复杂的三维定位装置,只能对经纬仪的静态精度进行检测,而跟 运动时,它们的相对位置的变化关系除了距离变化踪精度只能靠运动靶标来检测。可见,高空间分辨率与高辐射分辨率难以两全,它们之间必须有个折衷 遥感影像信息是对地面物体及特征的反映,而几乎所有的地学过程都依赖于尺度,如在某一空间尺度下表现为同一性质的目标在另一尺度下则呈现不同性质(goodchild,1980。3的滤波器为例图像处理 目标识别,该尺度层图像中9个像素点之一图2检测特征点与自身尺度层中其余8个点和在其之上及之下的两个尺度层9个点进行比较,共26个点,图2中标记&lsquo。

Yang等[]为了处理不同尺度的目标, 并且提高对候选区域的计算效率, 提出了两个策略, 统称为SDP-CRC.一个策略是采用与尺度相关的池化层(Scale-dependent pooling, SDP), 由于不同尺寸的物体可能在不同的卷积层上得到不同的响应, 小尺寸物体会在浅层得到强响应, 而大尺寸物体可能在深层得到强响应.基于这一思想, SDP根据每个候选区域的尺寸, 从对应的卷积特征图上池化特征.对于小尺度的候选区域, 从第三层卷积特征图上池化特征; 对于中等尺度的候选区域, 从第四层卷积特征图上池化特征; 对于大尺度的候选区域, 从第五层卷积特征图上池化特征.另一个策略是采用级联拒绝分类器(Cascaded rejection classifier, CRC), 快速排除一些明显不包含目标的候选区域, 只保留那些更可能包含目标的候选区域, 交由Fast R-CNN做最终分类.与Fast R-CNN相比, 该方法能够更加准确地检测小尺寸目标, 在平均检测精度和检测速度上都有很大提升.
-

-
故台城妓
而缩头缩脑只能招来更多的侵略
杨洋