科学网—深度学习在目标视觉检测中的应用进展与展望(2)
1.1.2 基于投票机制的区域建议
基于投票机制的方法主要用于基于部件的模型, 通常投票机制的实现可归纳为两步[13-14]: 1) 找到输入图像与模型中各个局部区域最匹配的区域, 并最大化所有局部区域的匹配得分; 2) 利用拓扑评价方法取得最佳的结构匹配.由于投票机制是一种贪心算法, 可能得不到最优的拓扑假设, 并且部件匹配通常采用穷举搜索来实现, 计算代价很高.
1.1.3 基于图像分割的区域建议
基于图像分割的区域建议建立在图像分割的基础上, 分割的图像区域就是目标的位置候选.语义分割是一种最直接的图像分割方法, 需要对每个像素所属的目标类型进行标注[15].目前主要采用的方法是概率图模型, 例如采用CRF[16]或MRF[17]方法来鼓励相邻像素之间的标记一致性.图像分割是一个耗时而又复杂的过程, 而且很难将单个目标完整地分割出来.
召回率,就是正样本被识别出的概率,计算公式为:。tpr(ture-pos-rt)=tp/(tp+fn) #正样本召回率,也是正类分对的概率。文档集合给出有关被检索 文档的一些线索用户提交 的一系列 的线索词 有时文档匹配器 可以对文档中的 某些词进行替换输入文档 匹配的文档 文本挖掘 文档匹配与线索匹 配的文档图1.5 检索匹配的文档召回率:recall,又称“查全率” 准确率:precision,又称“精度”、“正确率”可以把搜索情况表示:。
1.2 特征表示
这样,从每个子区域都可以得到一个 维向量,将所有子区域的向量按顺序排列在一起就组成 256(8 子区域中网格的划分目前收集到的样本只有 200套,为了减小过 高的特征维数和训练样本的不足给分类器参数估计 带来的问题,利用线性鉴别分析方法 对原始特征进行压缩。模型训练的参数优选如下:用skip-gram模型,采样阈值为10-5,训练窗口大小为5,输出向量维度为300,其它参数使用默认值,模型训练完成后即可以得到维度为300的词向量集合。这里需要补充的一点是,并不是参与分类的特征越多,分类的精度就越高,因为分类特征越多也可能带来特征冗余的现象,会造成计算量的增加,分类效率的降低,甚至是分类精度的降低。
1.2.1 手工设计的特征
在深度学习热潮之前, 主要采用手工设计的特征.手工特征数目繁多, 可以分为三大类:基于兴趣点检测的方法、基于密集提取的方法和基于多种特征组合的方法.
1) 基于兴趣点检测的方法
兴趣点检测方法通过某种准则, 选择具有明确定义并且局部纹理特征比较明显的像素、边缘和角点等[3].其中Sobel、Prewitt、Roberts、Canny和LoG (Laplacian of Gaussian)等是典型的边缘检测算子[26-29].而Harris、FAST (Features from accelerated segment test)、CSS (Curvature scale space)和DOG (Difference of Gaussian)等是典型的角点检测算子[30-32].兴趣点检测方法通常具有一定的几何不变性, 能够以较小的计算代价得到有意义的表达.
2) 基于密集提取的方法
4 3 特征提取的方法分类 3.1 颜色特征 3.1.1 颜色直方图 优点:它能简单描述一幅图像中颜色的全局分布,即不同色彩在整幅图像中所占的比例,特别适用于描述那些难以自动分割的图像和不需要考虑物体空间位置的图像。提取关键点和对关键点附加详细的信息(局部特征)也就是所谓的描述器可以称做是sift特征的生成,即从多幅图像中提取对尺度缩放、旋转、亮度变化无关的特征向量。 3.4 空间关系特征 提取图像空间关系特征可以有两种方法:一种方法是首先对图像进行自动分割,划分出图像中所包含的对象或颜色区域,然后根据这些区域提取图像特征,并建立索引。
3) 基于多种特征组合的方法
手工特征具有良好的可扩展性, 将兴趣点检测与密集提取相结合的多种特征组合方法, 能够弥补利用单一特征进行目标表示的不足. DPM (Deformable part-based model)[2]提出了一种有效的多种特征组合模型, 被广泛应用于目标检测任务并取得了良好效果, 例如行人检测[37-38]、人脸检测[39-40]和人体姿态估计[41]等.另外, 文献[42]提出了一种改进的DPM方法, 大大提升了检测速度.
依靠手工设计特征, 需要丰富的专业知识并且花费大量的时间.特征的好坏在很大程度上还要依靠经验和运气, 往往整个算法的测试和调节工作都集中于此, 需要手工完成, 十分费力.与之相比, 近年来受到广泛关注的深度学习理论中的一个重要观点就是手工设计的特征描述子作为视觉计算的第一步, 往往过早地丢失掉有用信息, 而直接从图像中学习到与任务相关的特征表示, 比手工设计特征更加有效[3].
1.2.2 自动学习的特征
近年来, 深度学习在图像分类和目标检测等领域取得了突破性进展, 成为目前最有效的自动特征学习方法.深度学习模型具有强大的表征和建模能力, 通过监督或非监督的方式, 逐层自动地学习目标的特征表示, 将原始数据经过一系列非线性变换, 生成高层次的抽象表示, 避免了手工设计特征的繁琐低效.深度学习在目标视觉检测中的研究现状是本文的核心内容, 将在第3节进行详细介绍.
1.3 区域分类
4结论从理论上讨论了面向对象方法中的训练样本数 量选择问题,给出了面向对象影像分类中选择训练 样本数量的理论依据,并通过TM影像分类实验,进 一步说明了训练样本数对分类精度的影响,指出了 万方数据 薄树奎等:训练样本数目选择对面向对象影像分类方法精度的影响1111 面向对象分类中的样本数量比通常的选取规则可以 大大减少,而且与所分析数据空问的复杂程度相关。oob 误差结果是 bagging 模型测试误差的有效估计,因为每一个样本的预测值都是仅仅使用不会进行拟合训练模型的样本。将被标记的原始数据集分成训练集和检验集两份,训练集用于训练分类模型,检验集用于评估分类模型性能。

2 目标视觉检测的公共数据集
为了促进目标视觉检测的研究进展, 建设大规模的公共数据集成为必然要求.目前, 目标视觉检测研究常用的公共数据集有ImageNet、PASCAL VOC、SUN和MS COCO等.下面将从这些数据集包含的图像数目、类型数目、每类样本数等方面对它们进行介绍.直观对比如图 2所示.
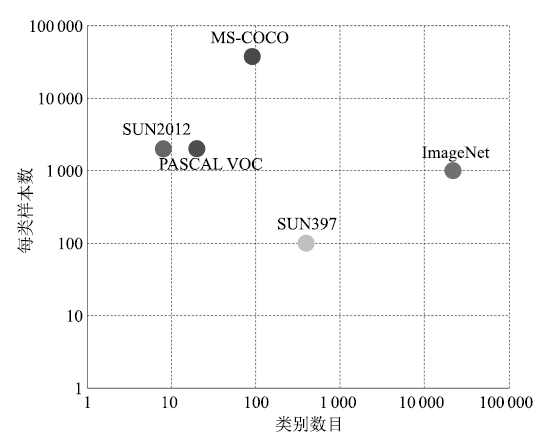
图 2 几种公共数据集的对比图
Figure 2 Comparison of several common datasets
1) ImageNet数据集[]
该数据集是目前世界上最大的图像分类数据集, 包含1 400万幅图像、2.2万个类型, 平均每个类型包含1 000幅图像.此外, ImgeNet还建立了一个包含1 000类物体, 有120万图像的数据集, 并将该数据集作为图像识别竞赛的数据平台.
2) PASCAL VOC数据集[]
2005 ~ 2012年, 该数据集每年都发布关于图像分类、目标检测和图像分割等任务的数据集, 并在相应数据集上举行算法竞赛, 极大地推动了计算机视觉领域的研究进展.该数据集最初只提供了4个类型的图像, 到2007年稳定在20个类; 测试图像的数量从最初的1 578幅, 到2011年稳定在11 530幅.虽然该数据集类型数目比较少, 但是由于图像中物体变化极大, 每幅图像可能包含多个不同类型目标对象, 并且目标尺度变化很大, 因而检测难度非常大.
3) SUN数据集[]
4 3 特征提取的方法分类 3.1 颜色特征 3.1.1 颜色直方图 优点:它能简单描述一幅图像中颜色的全局分布,即不同色彩在整幅图像中所占的比例,特别适用于描述那些难以自动分割的图像和不需要考虑物体空间位置的图像。 本实验中的原始图像 (i) 均来自 sfu greyball 数据集 [15] 中,并将原始图像按照数据集所提供的光源颜色真值 e 1 = [r 1 ,g 1 ,b 1 ] 校正后的图像作为目标图像( i ),该数据集中一共包含 15 个不同的场景下来自不同光源的 11346 张图片。图像可采用其几何特性描述物体的特性,一般图像的描述方法采用二维形状描述,它有边界描述和区域描述两类方法。
4) MS COCO数据集[]
该数据集包含约30多万幅图像、200多万个标注物体、91个物体类型.虽然比ImageNet和SUN包含的类型少, 但是每一类物体的图像多, 另外图像中包含精确的分割信息, 是目前每幅图像平均包含目标数最多的数据集. MS COCO不但能够用于目标视觉检测研究, 还能够用来研究图像中目标之间的上下文关系.
3 深度学习在目标视觉检测中的应用进展
3.1 深度学习简介
深度学习模型具有强大的表征和建模能力, 通过监督或非监督的训练方式, 能够逐层、自动地学习目标的特征表示, 实现对物体层次化的抽象和描述. 1986年, Rumelhart等[]提出人工神经网络的反向传播(Back propagation, BP)算法. BP算法指导机器如何从后一层获取误差而改变前一层的内部参数, 深度学习能够利用BP算法发现大数据中的复杂结构, 把原始数据通过一些简单的非线性函数变成高层次的抽象表达[], 使计算机自动学习到模式特征, 从而避免了手工设计特征的繁琐低效问题. Hinton等[-]于2006年首次提出以深度神经网络为代表的深度学习技术, 引起学术界的关注.之后, Bengio[]、LeCun[]和Lee[]等迅速开展了重要的跟进工作, 开启了深度学习研究的热潮.深度学习技术首先在语音识别领域取得了突破性进展[].在图像识别领域, Krizhevsky等[]于2012年构建深度卷积神经网络, 在大规模图像分类问题上取得了巨大成功.随后在目标检测任务中, 深度学习方法[, , ]也超过了传统方法.
目前应用于图像识别和分析研究的深度学习模型主要包括堆叠自动编码器(Stacked auto-encoders, SAE)[]、深度信念网络(Deep belief network, DBN)[-]和卷积神经网络(Convolutional neural networks, CNN)[]等.
SAE模型的实质是多个自动编码器(Auto-encoder, AE)的堆叠.一个自动编码器是由编码器和解码器两部分组成, 能够尽可能复现输入信号.作为一种无监督学习的非线性特征提取方法, 其输出与输入具有相同的维度, 隐藏层则被用来进行原始数据的特征表示或编码. SAE模型将前一层自动编码器的输出作为后一层自动编码器的输入, 逐层地对自动编码器进行预训练, 然后利用BP算法对整个网络进行微调.目前基于SAE的扩展模型有很多, 例如, 堆叠去噪自动编码器(Stacked denoising autoencoders, SDA)[], 以及堆叠卷积自动编码器(Stacked convolutional auto-encoders, SCAE)[].
sae的构建过程与dbn类似,模型构建过程见.训练得到第一个ae后,将其隐藏层作为输入,用同样的方法可训练第二个ae,依次类推可训练得到多个ae.依次将多个ae堆叠在一起,便构成sae模型,此时sae的最后一层是输入数据经过多次变换处理后得到的抽象特征.最后再根据问题不同设定,连接不同的输出层,通过有监督学习算法训练输出层的权值,从而得到最终分类结果.。如果将靠近输入层的部分替换为贝叶斯信念网络,即有向图模型,而在远离输入层的部分仍然使用rbm,则称为深度信念网络(deep belief networks,dbn)。2、将防火墙连接至网络,在任意一台连通内网的电脑浏览器中输入防火墙的初始ip和管理端口:[img]:81 ,输入初始用户名admin 和密码123456 即可打开防火墙的管理界面:。
CNN是图像和视觉识别中的研究热点, 近年来取得了丰硕成果. 给出了由LeCun等[]提出的用于数字手写体识别的CNN网络结构, CNN通常包含卷积层、池化层和全连接层.卷积层通过使用多个滤波器与整个图像进行卷积, 可以得到图像的多个特征图表示; 池化层实际上是一个下采样层, 通过求局部区域的最大值或平均值来达到降采样的目的, 进一步减少特征空间; 全连接层用于进行高层推理, 实现最终分类. CNN的权值共享和局部连接大大减少了参数的规模, 降低了模型的训练复杂度, 同时卷积操作保留了图像的空间信息, 具有平移不变性和一定的旋转、尺度不变性. 2012年, Krizhevsky等[]将CNN模型用于ImageNet大规模视觉识别挑战赛(ImageNet large scale visual recognition challenge, ILSVRC)的图像分类问题, 使错误率大幅降低, 在国际上引起了对CNN模型的高度重视, 也因此推动了目标视觉检测的研究进展.
-

-
陈云柳
你他喵的事看热闹不嫌事大
-
郝彦杰
韦德只是比俺们厂子工资高许多
您为光棍出了很好的主意