就是的特点是不需要有监督数据集2模型数据模型
就是的特点是不需要有监督数据集2模型数据模型
1 论文主要内容
使用 C4 或维基百科数据集来训练文档问题编码器。最大的特点是不需要有监督的数据集
2 模型与数据
模型架构:BERT+AvgPool 评分方式:Vector Cos值乘以BM25,乘以BM25 论文中有个高大上的名字叫Lexicon Enhanced Dense Retrieval (LEDR)
训练样本的构建方式有两种: 1) Inverse Cloze Task (ICT): 从doc中取一个句子作为query,这个doc是一个positive example 2) Dropout as Positive Instance (DaPI): query或doc是dropped一次,就是SimCSE
3种训练方法
Step1:固定query-encoder或doc-encoder,为了便于表达,假设doc-encoder是固定的
Step2:获取一批docs并生成相应的query,即获取数据(q,d)
Step3:使用SimCSE得到相似句子表示,即得到数据(q,q',d)
Step4:计算query-query的loss,其实这就是SimCSE:
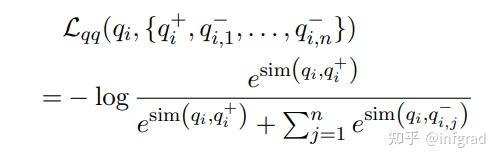
Step5:计算query-doc的损失。除了使用in-batch doc外,还使用了之前的batches doc。这些doc存储在一个FIFO队列中,其实就是MOCO的思路:
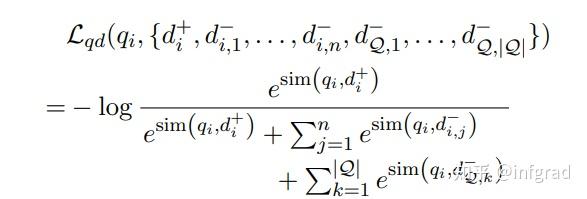
Step6:加入上面两个loss进行优化
Step7:按照步骤1-6训练一定步数后,将q-encoder的权重复制到d-encoder,然后固定q去训练d 备注:从Step7开始,和Step1-6类似,并且损失函数是:
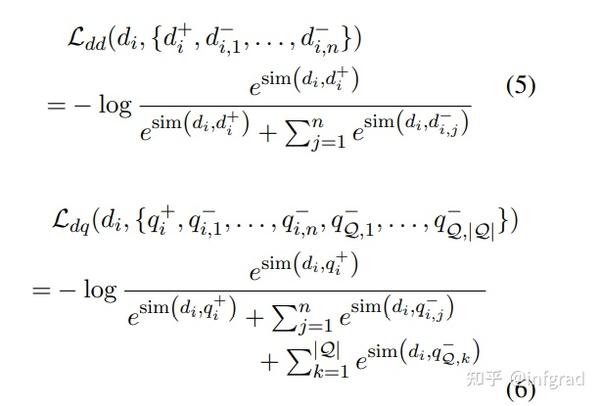
第一个损失函数是doc-doc,d+是通过SimCSE得到的,第二个损失函数是qd的损失函数,q有两个来源:ICT和历史队列。
整个训练过程就是反复固定q-encoder和d-encoder进行训练。
3.1 个人对缓存队列的理解
整个训练过程比较复杂的是固定q或者d依次训练另外一个。其实q和d是共享权重的,因为训练完一个encoder之后,这个encoder的权重会被复制,所以最后共享权重。. 那么,为什么要采用反复固定训练的方法呢?原因是为了增加简化反例的数量(也就是更大的batch),使用了vector cache queue。缓存队列最大的问题是发送到队列的文本编码在某一时刻并没有使用模型,因为模型是不断更新的。因此,固定q和d可以解决这个问题。如果一个encoder是固定的,假设是q,那么qq的损失函数就不用队列了,是in-batch,一切ok,qd的损失函数会用到d的缓存队列队列训练教案下载,因为d是固定的,所以缓存队列中的d是由一个模型生成的。因此,与其固定 q 和 d 去训练另一个编码器,不如固定模型在某个时刻固定负例队列的文本表示,然后从那个时刻开始继续训练。建议结合MOCO阅读。以下为论文原文:
缓存的表示位于不同的隐藏空间中。尽管 MoCo 和 xMoCo 中的快速编码器都是随动量更新的,但队列中已经编码的表示永远不会更新。这会在训练期间在新编码和缓存的旧表示和噪声之间造成语义不匹配。在 ICoL 中,用于对比学习的所有表示都在同一隐藏空间中对齐。此外,ICoL 比 xMoCo 更灵活,因为它没有引入额外的快速编码器队列训练教案下载,甚至其查询编码器和文档的权重也被编码器共享。
但我还有一个问题。在qd的损失函数中,queue的文本向量是一个空格,但是queue会用in-batch的反例进行训练。他们不是一个空间。是因为不一致的程度变小了吗??这是更深奥的形而上学。
4 实验结果
实验结果如下:
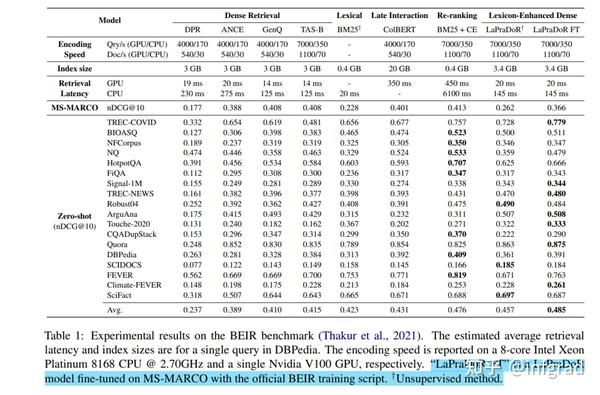
可以看到,即使在MS数据集上没有fine-tune,也超过了BM25,还是很不错的。然后作者又做了3个实验:
4.1 LEDR对结果的影响:
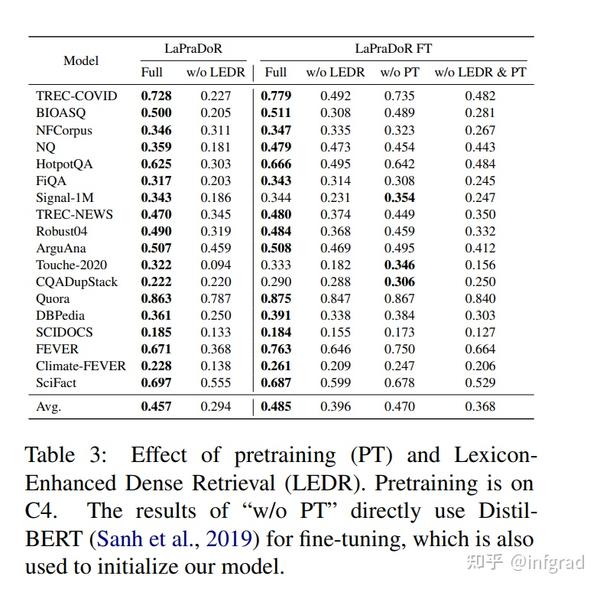
这里的LEDR指的是乘以BM25的分数,w/o表示没有,我们遗憾的发现LEDR很重要,那套极其复杂的预训练方法收效甚微。
4.2 数据增强方式对效果的影响:
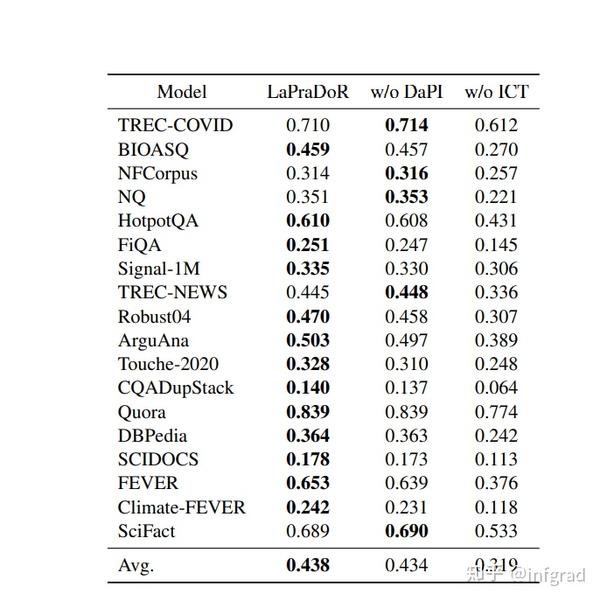
可以发现ICT非常重要。我怀疑如果没有ICT,连q都生产不出来,qd也训练不出来。效果一定不好。
4.3 各种反例队列算法对效果的影响:
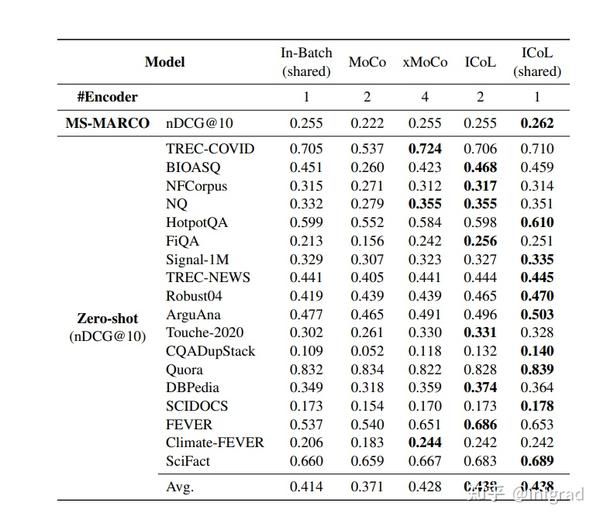
ICoL是论文中提出的方法,自然是最好的,是否共享权重也是最好的。最糟糕的是 MOCO,令人惊讶的是,纯 In-Batch 并没有那么糟糕。
5 总结
最后总结: 整体感觉很不错的paper,但是不得不说bm25真的太强了,没有bm25做enhancement,pre-training几乎没有任何价值,比bm25差远了。换个角度想,这也证明了qd编码真的很难。
模型制作的概念与分类、材料、建筑模型及配景制作

《手工模型制作技术教学视频》结合现代设计发展的需要,系统全面地介绍了模型制作的基本步骤。解说员深入浅出地介绍了模型的概念和分类、模型制作的工具和材料,以及工业产品模型制作。、建筑模型和背景制作等专业理论知识,具有很强的学习性。
工业设计、建筑设计、环境艺术设计及相关专业。模型是对现实世界中的对象、现象、过程或系统的简化描述,或者是对其某些属性的模仿。从广义上讲,它是指在设计中模仿实物的形状或结构而制成的原型,其尺寸可分为缩小型、实物型和放大型。有些模型甚至精确到真实事物的确切细节,而其他模型则只是模仿真实事物的主要特征。模型的意义在于它可以通过视觉了解物体的形象。除具有艺术欣赏价值外,在教育、科学研究、工业建设、土木工程和军事等方面也有很大的实用价值。随着科学技术的进步,人们把研究对象看成一个系统,从整体行为来研究。这种系统的研究,不是要罗列所有的事实和细节,而是要找出具有重大影响的因素和相互关系,从而把握本质规律。对于所研究的系统,可以通过类比和抽象的方法建立各种模型。这称为建模。通过类比和抽象可以建立各种模型。这称为建模。通过类比和抽象可以建立各种模型。这称为建模。
模型类型
模型可以采用多种不同的形式。模型可以分为物理类和非物理类。实物模型,如“天坛·祈年殿”模型、汽车模型等;非物理模型,例如经济模型、软件模型、管理模型等。物理模型是现有或正在建设中的真实对象的小型模仿或原型。非物理模型是指对一个系统、一个理论或一类现象的一般的、本质的、抽象的或直观的描述。
按模型形式可分为物理模型、数学模型、结构模型和仿真模型。
物理模型
又称物理模型,可分为物理模型和模拟模型。①物理模型:根据相似理论,将物理对象按比例缩小原系统(也可以放大或与原系统大小相同),如风洞实验中的飞机模型,液压系统实验模型、建筑模型、船模型等。② 类比模型:在不同物理领域(力学、电学、热学、流体力学等)的系统中,各个变量有时服从同一规律,可以根据这个共同规律和类比做出物理意义完全不同的类比楷模。例如,在某些条件下,由节流阀和气体电容器组成的气动系统的压力响应与电阻和电容器组成的电路的输出电压特性具有相似的规律,因此可以使用相对容易实验的电路来模拟气动系统。.
数学模型
用数学语言描述的一类模型。数学模型可以是一个或一组代数方程、微分方程、差分方程、积分方程或统计方程,或它们的某种适当组合,通过它可以定量或定性地描述系统各变量之间的关系。相关性或因果关系。除了方程描述的数学模型外,还有代数、几何、拓扑、数理逻辑等其他数学工具描述的模型。需要指出的是,数学模型描述的是系统的行为和特征,而不是系统的实际结构。
结构模型
主要反映系统结构特征和因果关系的模型。结构模型中一类重要的模型是图形模型。此外,生物系统分析中常用的隔室模型(参见 Compartmental Model Identification)也是结构模型。结构模型是研究复杂系统的有效手段。
模拟模型
由在数字计算机、模拟计算机或混合计算机上运行的程序表示的模型。物理模型、数学模型、结构模型一般都可以使用合适的仿真语言或程序转化为仿真模型。关于不同控制策略或设计变量对系统的影响,或某些扰动对系统可能产生的影响的实验,最好在系统本身上进行,但这并不总是可能的。原因有很多,例如:实验费用可能很贵;系统可能不稳定,实验可能会破坏系统的平衡,造成危险;系统时间常数大模型制作教案下载,实验时间长;要设计的系统还不存在等。在这种情况下,建立系统的仿真模型是有效的。例如,生物甲烷化是厌氧发酵过程,其中由于细菌分解产生甲烷。根据生物化学知识,可以建立过程的模拟模型,通过计算机求得过程的最佳稳态值,研究各种启动方法。这些研究几乎不可能在系统本身上进行,因为在技术上很难保持该过程处于稳定状态,而且生物甲烷化反应启动缓慢,需要数周时间。但如果在计算机上使用(模拟)模型进行模拟,甲烷化反应的启动过程只需要几分钟。生物甲烷化是一种厌氧发酵过程,其中由于细菌分解而产生甲烷。根据生物化学知识,可以建立过程的模拟模型,通过计算机求得过程的最佳稳态值,研究各种启动方法。这些研究几乎不可能在系统本身上进行,因为在技术上很难保持该过程处于稳定状态,而且生物甲烷化反应启动缓慢,需要数周时间。但如果在计算机上使用(模拟)模型进行模拟,甲烷化反应的启动过程只需要几分钟。生物甲烷化是一种厌氧发酵过程,其中由于细菌分解而产生甲烷。根据生物化学知识,可以建立过程的模拟模型模型制作教案下载,通过计算机求得过程的最佳稳态值,研究各种启动方法。这些研究几乎不可能在系统本身上进行,因为在技术上很难保持该过程处于稳定状态,而且生物甲烷化反应启动缓慢,需要数周时间。但如果在计算机上使用(模拟)模型进行模拟,甲烷化反应的启动过程只需要几分钟。可以建立过程的仿真模型,通过计算机寻找过程的最优稳态值,研究各种启动方法。这些研究几乎不可能在系统本身上进行,因为在技术上很难保持该过程处于稳定状态,而且生物甲烷化反应启动缓慢,需要数周时间。但如果在计算机上使用(模拟)模型进行模拟,甲烷化反应的启动过程只需要几分钟。可以建立过程的仿真模型,通过计算机寻找过程的最优稳态值,研究各种启动方法。这些研究几乎不可能在系统本身上进行,因为在技术上很难保持该过程处于稳定状态,而且生物甲烷化反应启动缓慢,需要数周时间。但如果在计算机上使用(模拟)模型进行模拟,甲烷化反应的启动过程只需要几分钟。需要几个星期。但如果在计算机上使用(模拟)模型进行模拟,甲烷化反应的启动过程只需要几分钟。需要几个星期。但如果在计算机上使用(模拟)模型进行模拟,甲烷化反应的启动过程只需要几分钟。
数字模型
数字模型又叫数字沙盘、多媒体沙盘、数字沙盘系统等,以三维方式建模,模拟三维建筑、场景、效果,可以自由行走、奔跑、飞翔,并放大数字场景,从整体到局部再从局部到整体,没有限制。以3D数字技术打造的3D数字城市,虚拟样板间,交通桥梁模拟,园林规划3D可视化,古建筑3D模拟,机械工业设备模拟演示,借助PC、显示系统等进行展示, explain, command, explain 等效果。
数字模型通过声、光、电、图像、三维动画和计算机程序控制技术与实物模型融为一体,能充分体现展示内容的特点,达到生动多变的动态视觉效果。对参观者来说是一种全新的体验,能够引起强烈的共鸣。数字模型是国内规模最大、最早的模型设计制作公司深圳赛业模型提出的新概念。自主研发的数字仿真技术获得国家专利,并在韶关市规划局和韶关市总体规划项目中得到体现。新名词数字模型将在不久的将来取代传统的建筑模型,成为展示内容的又一新亮点。数字模型超越了单调的实物模型沙盘展示方式。在传统沙盘的基础上,加入多媒体自动化程序,充分展现场地特征、季节变化等丰富的动态视觉效果。对顾客来说是一种全新的体验,能产生强烈的视觉震撼感。客户还可以通过触摸屏选择观看相应的展示内容,简单方便,大大提高了整个展示的交互效果。对顾客来说是一种全新的体验,能产生强烈的视觉震撼感。客户还可以通过触摸屏选择观看相应的展示内容,简单方便,大大提高了整个展示的交互效果。对顾客来说是一种全新的体验,能产生强烈的视觉震撼感。客户还可以通过触摸屏选择观看相应的展示内容,简单方便,大大提高了整个展示的交互效果。
-

-
相原光一
很多家里人就等你掉坑里然后往下扔石头
-
-
张昆
长方应查明原因
连伊拉克现政府都不再信任你美爹